The 2025 International Mathematical Olympiad
IMO 2025 just finished. A bunch of AI models gave it a shot this year. Here’s my take on the results.
Grand Challenge
Since the IMO Grand Challenge was proposed in 2020, winning a gold medal at the IMO has been seen as an important AI milestone, with a lot of speculation and disagreement about when it would be accomplished. I remember the topic coming up at a large dinner with AI researchers at Neurips 2022, where most folks thought we were nowhere close to getting there, and several opining that it wouldn’t happen before 2030. Someone on the (then secret) AlphaProof team made a bet that it’d happen in 2024, and people literally laughed. This was back when frontier LLMs struggled to reason about substantially simpler math puzzles, and there wasn’t a clear way forward.
This was famously the subject of a bet between Eliezer Yudkowsky and Paul Christiano, with the more optimistic prediction being “>16% chance by the end of 2025” by EY. There have been several prediction markets tracking this question as well, notably this one on manifold.
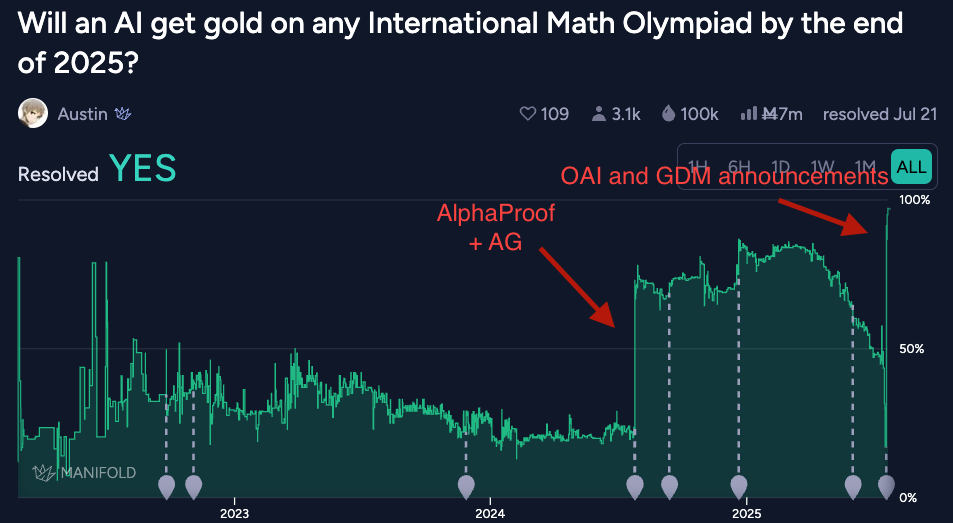
The IMO Grand Challenge fell this year.1 Both Google DeepMind and OpenAI announced that their models achieved gold medal performance.
My connection to the problem
I spent almost 2 years at Google DeepMind working on this problem, culminating in us announcing AlphaProof after IMO 2024. Together with AlphaGeometry, it got to silver medal performance, missing gold by one point. This came as quite a shock to both the AI and math communities.
There were a few reasons why this didn’t constitute beating the IMO Grand Challenge:
- The system didn’t get a gold medal.
- Solutions for some of the problems took a long time, with the longest taking almost 3 days, which is more than the 4.5 hours given to humans.
- The problems were first translated from English to Lean by humans.
It felt like we’d come very close though.
Re (1), we missed a gold medal by 1 point. There are 6 problems worth 7 points each — the system got 28 points, and the gold cutoff that year was 29. This was despite it being an unlucky topic distribution relative to the system’s strengths. The system was weakest at combinatorics, and the two problems AlphaProof didn’t solve (P3 and P5) were combinatorics problems. Historically, there’s been two combinatorics problems less than half the time.
Re (2), this could be fixed with some more work. And re (3), for the problems AlphaProof had solved, the system could also successfully autoformalize them (though this wasn’t used in the competition setting).
This prompted the AlphaProof team to move on from the IMO to harder math problems, and in part prompted me to move to Anthropic to work on agentic coding. So it was fun for me to watch from the sidelines as a bunch of AI companies competed to be the first to claim the gold medal this year — disinterested, but not uninterested.
This year’s results
If I had to predict how AI models would do at this year’s IMO, I’d have been quite bullish on at least some AI systems getting a gold medal. Some Lean-based system getting there felt almost guaranteed given last year’s results.
But given that the big labs are interested in general LLM reasoning, doing it in Lean again would be a bit of a distraction. Both Google DeepMind and OpenAI had trialed general LLMs on the IMO in 2024, but the systems weren’t strong enough to get there at the time. The pace of progress since has been insane, but I’d still only have given it a 50% chance that a general LLM would get a gold medal.
The problems
The problems broke down as 2 combinatorics, 2 number theory, 1 geometry and 1 functional inequality (though several problems fell in multiple categories). Like last year, I found the Dedekind cuts Youtube channel great for understanding the problems and solutions. Keeping with the tradition of having the problems themed around the place where the contest is held, the problems featured a bunch of Australian references, including the term “inekoalaty”.
The contestants found the problems easier than last year, with the gold cutoff being 35/42 this time. A lot of students were tied at 35, so they gave out 72 gold medals (vs 58 last year). This effectively lowered gold medal cutoff, combined with the fact that the cutoff lined up with problem boundaries (ie 5/6 put you exactly on the line) made it a good year for AI attempts.
OpenAI
OpenAI were the first to announce their results on Friday night. They did it entirely in natural language, without tools, and within 4.5 hours.
The proofs are here. They are quite strange. For one, the model is extremely terse, abbreviating wherever possible, not bothering to write in full sentences or even correct grammar. It also throws in periodic words of self-encouragement like “Good.” or “Perfect.”
“That's full. That's precisely. Done."
— OpenAI's IMO model, on finishing P5
They talked a bit about their method in this interview. They say they’ve unlocked a way to do RL against hard-to-verify tasks. It seems to have been a very small team that worked on this.
Google DeepMind
Google DeepMind followed OpenAI’s announcement on Monday. Again, in natural language and within 4.5 hours. They also had the IMO vet their proofs and attest to the gold medal performance.
The proofs are here. These proofs look much more polished than OpenAI’s, almost indistinguishable from a well-written human proof.
From the acknowledgements, it looks like a large team worked on this, including a lot of folks from the 2024 attempt. There seems to have been a mix of several techniques, including parallel test-time compute, RL, translated formal proofs, RAG over previous solutions, and prompting/scaffolding. They released a light version of this system which also does well on non-math reasoning tasks.
Formal systems
A couple formal systems also made a claim to a gold medal.
ByteDance announced Seed-Prover, which solved P1-P5 but needed 4 days. The proofs are somewhat insane, eg P1 is proved in >4k lines. Their technique relies on both formal and natural language data, and their test-time scaling uses library learning and test-time conjecture generation.
Harmonic, a lean-focused startup, also claimed a gold medal. Their proofs are more readable but still extremely long, eg P1 is >1.4k lines. I’d thought AlphaProof’s P6 solution last year was long, and that was just 300 lines. They didn’t share much detail on their protocol — it sounds like they may have run for longer than ByteDance, and it’s not clear what model was used to generate the answers, and whether they trained their own base model.
My take on the results
The results from both OpenAI and Google DeepMind are extremely impressive. In particular, if what OpenAI says about this technique of doing RL on unverifiable tasks being general enough to scale to other hard tasks holds up, that sounds very promising. It’s clear from the proofs that the model has been aggressively RL’d. My guess would be it’s a grader model trained to make use of reference solutions in some form, coupled with some RL tricks to prevent reward hacking, but I could easily be wrong.
Aside on credibly grading AI IMO solutions
Having gone through the process of trying to grade AI solutions to the IMO last year as one of the leads of Google DeepMind’s 2024 IMO effort, there are more nuances than one might think.
Ideally, there would be a single system, and it would be frozen before the contest. The problem would go in, the system would think, and at some point it would spit out its answer. The answer would be graded by IMO judges, and points would be awarded.
In practice, this level of rigor is very hard to achieve, and I doubt any of the systems this year achieved it. Examples of reasonable-seeming things a team may do that would violate this protocol:
- Manually running and re-running commands, fixing bugs that arise.
- Toggling compute, run time, and other parameters, possibly in response to the problem distribution.
- Not clarifying the protocol being used beforehand, making a lot of decisions contingent on how well the model is actually doing. Eg if one of the teams didn’t get the IMO gold result in 4.5 hours, it’s very possible they would run for longer than 4.5 hours, re-grade, and report those results.
- Evaluating multiple systems, and only reporting results for the one that performed best.
Terry Tao had a good post about this. Ideally, this would be done in an official contest setting. Short of that, having external graders and invigilators (as we did in 2024) adds a lot of value. In this light, I’d say Google DeepMind’s claim is the most credible, because (a) it was externally vetted and (b) it was a large team going at this problem a second time with an opportunity to refine the protocol.
In a sense these are minor quibbles — having an AI system that has these problems within reach is the real achievement, and the rest is splitting hairs.
On the Lean-based provers, looking at the benchmark numbers ByteDance released, the proving strength is similar to AlphaProof last year. But now that we have off-the-shelf base models that can apparently be scaffolded to elicit gold-level solutions in plain English, it’s a lot harder to justify using Lean with several days of compute to solve the same problems.
On the nature of AI research
The IMO story highlights a couple aspects of AI research right now that I want to dwell on.
Energy and momentum
There is so much momentum behind AI right now that it feels like we could crack almost any problem if enough people pour their energy into it. There’s almost nothing that doesn’t move if you push.
Most research breakthroughs are not special
OpenAI and Google DeepMind got to the exact same result using techniques that are quite different. ByteDance got to a similar Lean proving strength as AlphaProof last year using a very different approach.
This is true of a lot of AI progress right now. There’s a lot of good ideas that should work, and no lab has the resources to try all of them. Also, the techniques that work may be path dependent — they work best with the setup / infrastructure / people of a particular lab. And there is a rising tide in capabilities coming from scaling, which keeps changing the landscape of approaches that might work.
There are definitely some breakthroughs that are “bottlenecks”, in that everyone needs to converge on the same insight to make progress (an obvious one being transformers). But many other “breakthroughs” are not special.
The future
I expect there will still be some interest in AI attempts at the IMO next year. Frontier LLMs will likely be able to get a medal out of the box, without any specialization.
Talking to mathematicians, I get the sense that cracking some non-trivial (but not super exciting) open problem is “not that hard” relative to current capabilities. I expect this will happen within the next 6 months.
Lean still has an important role to play in AI for math. In some ways, the strengths of Lean become more apparent as we move to harder and harder problems, where it gets prohibitively hard to judge the correctness of proofs. The current paradigm of theorem proving research is “lean-specialized base model, lots of test-time compute”. This made a lot of sense when larger base models weren’t much good at natural language math proofs. The extra compute was better spent generating more plausible proof candidates with a smaller specialized model, since Lean would tell you when you’ve found the answer. I think it now makes sense to flip this, and build both skills into the same model.
Having personally evaluated LLMs on IMO problems several times over the last 3 years, it is astounding to me how far they’ve come. I remember manually going through Gemini and GPT-4’s solutions to every recent numerical solution IMO problem in mid 2023, and finding only one problem on which it deserved partial points (the rest being zeroes). A gold medal with 5/6 just 2 years later represents an insane speed of progress. If you’re in the weeds trying to make the model better at whatever thing it is that it currently sucks at, it can be easy to miss the bigger picture.
The other domain in which I viscerally “feel the AGI” is agentic coding. The current crop of models is in a different league compared to anything that came before, and I can start to connect the dots forward to where we will be next year and the year after that. This is going to happen for many other domains, and if you haven’t felt it in your domain yet, it is just a matter of time.
1 The original wording requires the model to be open source, so technically it hasn’t fallen yet, but this feels like a minor quibble.